Published on
Digitization of a vintage book with ImageMagick: Sobron Aidit's ‘Derap Revolusi’
Ever since my senior year of high school, I had this hobby of reading and collecting vintage books. This year, I want to start digitizing things to make access to them – if possible – easier.
By coincidence, I came across one work by an Indonesian author (Sobron Aidit) titled Derap Revolusi (The March of the Revolution) which was published in 1962 by Lembaga Kebudajaan Rakjat (Institute for the People’s Culture). The institute was dissolved around 1965 and their works were banned though the study of their materials is still allowed in some cases, however, I could not find this book’s file on the internet.
Preserving literary treasures is essential in our digital age, ensuring that classic works remain accessible for future generations. To do the task of digitization, I decided to use ImageMagick to convert my two-page PDF scans of the book into a more reader-friendly one-page format.
To see the end product (one of the novelette): click here. To see the process of digitizing it, keep reading.
The process herein required precise cropping and a thorough understanding of the PDF layout—specifically, the width, height, and offsets. After the initial scans, several issues emerged. Some images were misaligned, needing different offsets, while others were partially unreadable and had to be rescanned. By converting the PDF to PNG format and utilizing macOS’s Preview app, I was able to measure and adjust the cropping accurately.
To do accurate cropping I must:
- know the layout of the PDF (width of the crop area in pixels, height of the crop area in pixels, horizontal offset, vertical offset)
- see if any special cases need different layouts.
After waiting some time for the first scan, the result came back and it looked like this:

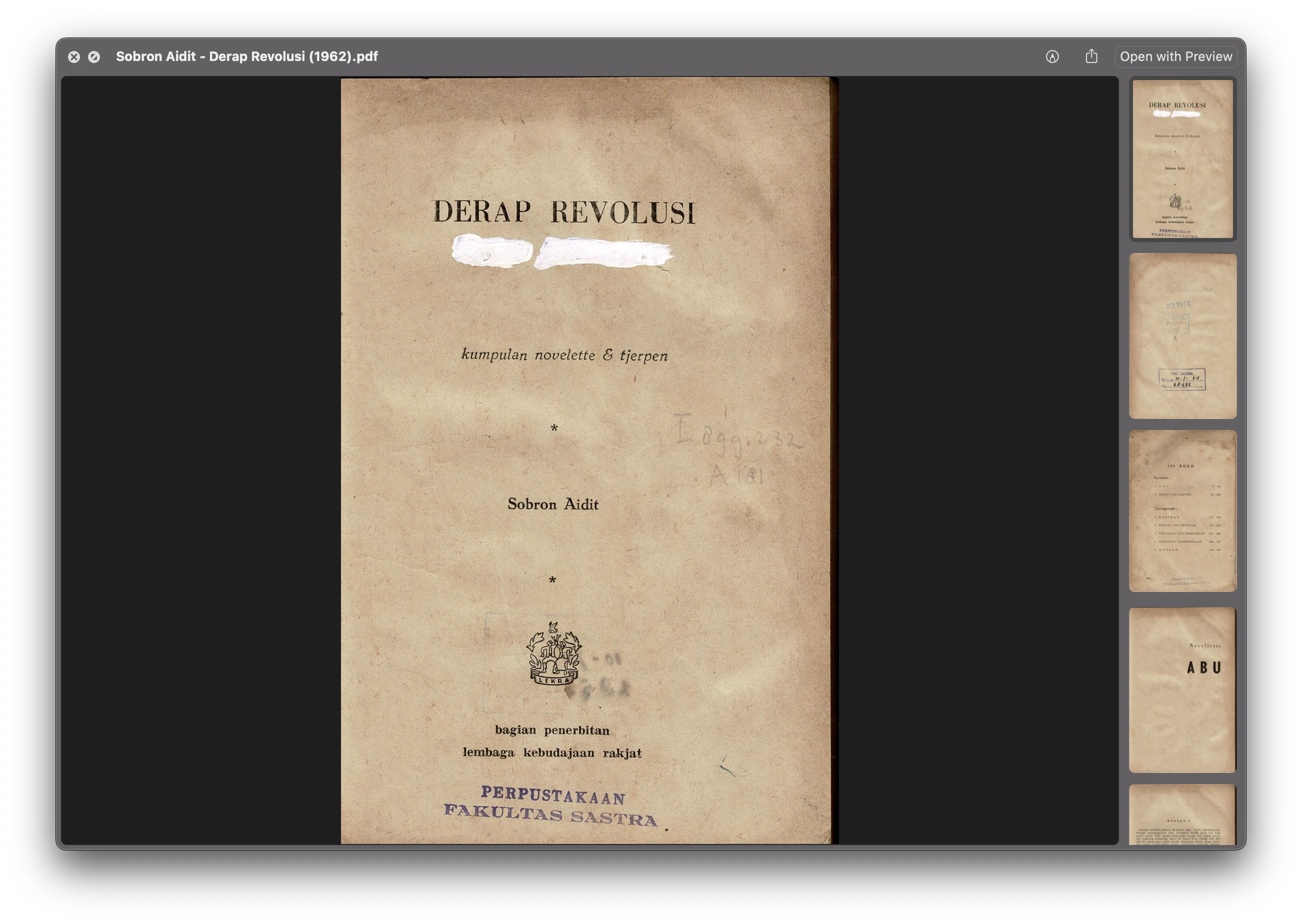
image1. first two pages of the book
image2. page 8 and 9 of the book
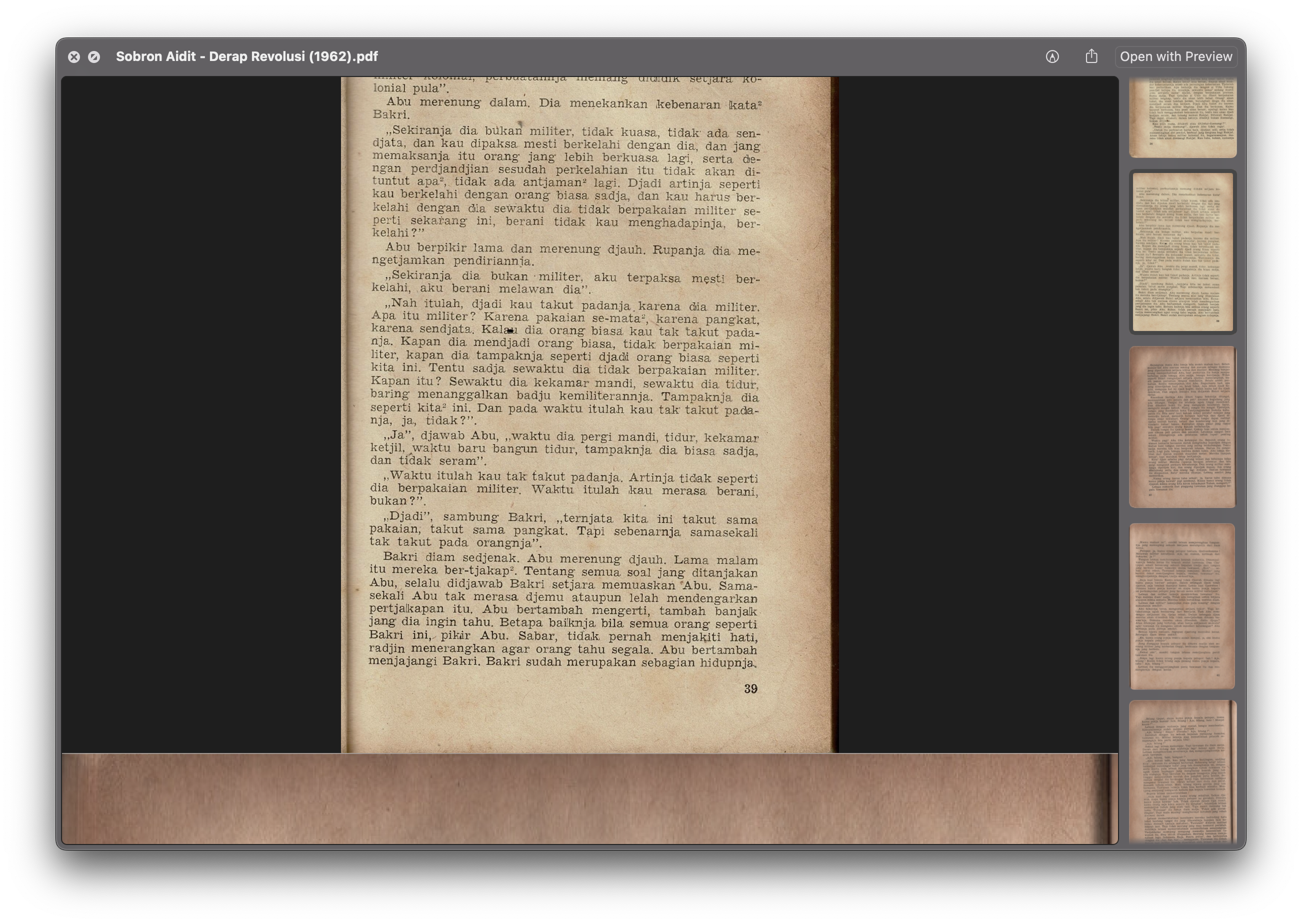
image3. page 38 and 39 of the book, scanning error shown
image4. page 68 and 69 of the book, showing difference in page position
You can see a few problems with the last two images:
image4has a different position thanimage2and thus needs a different offset.image3was not correctly scanned and its contents are not intelligible for the right side. Thus, not only does it need a different offset, it needs to be scanned again and it would yield a different cropping layout.
For the first problem, the fix was quite simple. I converted my 300 dpi PDF into a bunch of PNGs (magick -density 300 INPUT_FILE.pdf image.png) where they would then be named with indexes ranging from image-0.png to image-94.png composed of 188 pages of the book. I then used the Preview app on macOS and could easily see and measure the layout and the offset.
image5. Measuring layout (the dimension yielded here would be different from what I end up using)
image6. Measuring the horizontal offset (see the 288 value)
The layout of image1 as shown in image5 and image6 can now be easily cropped with the following bash script and don’t forget to change the permission (chmod +x) of the file.:
#!/bin/bash
for i in {1..19}; do
# Calculate the output indexes
index1=$(( (i - 1) * 2 + 1 ))
index2=$(( (i - 1) * 2 + 2 ))
# Crop left page
magick "image-$i.png" -crop 1360x2100+230 "first_cropping-$index1.png"
# Crop right page
magick "image-$i.png" -crop 1360x2100+1600 "first_cropping-$index2.png"
done
The final dimensions I calculated for the layout of image2 are as follows:
- 1360 pixels for the width of the crop area
- 2100 pixels for the height of the crop area
- 230 for the horizontal offset for the left page, 1600 for the right page
For image4, a different approach is taken:
As the offset is different, I experimented by not adding an offset to it. Write this into a bash file and don’t forget to change the permission (chmod +x) of the file.
#!/bin/bash
for i in {26..94}; do
# Calculate the output indexes
index=$(( (i - 1) * 2 + 1 ))
# Crop only once
magick "image-$i.png" -crop 1394x2091 "second_cropping-$index.png"
done
The cropping was terrific:


But there were some side effects of not specifying an offset. The remaining layout of the image that wasn’t cropped was yielded by ImageMagick as residues, albeit it was easy to dispose of them as the residues had names ending in -{2,3,4,5}.png and bash could just remove them by looping.
As for the badly scanned parts of image3, I ended up scanning them again but the principles are still the same. Measure the layout and the offset and just crop them en masse. The end products are as follows:
Since the size is different, the Preview app automatically squeezes them out. That being said I am satisfied with the cropping script written here since it helped me save a lot of time in digitization this book from decades ago.
Discussion and feedback